-----シェルのスキル集大成-----






















.jpg)

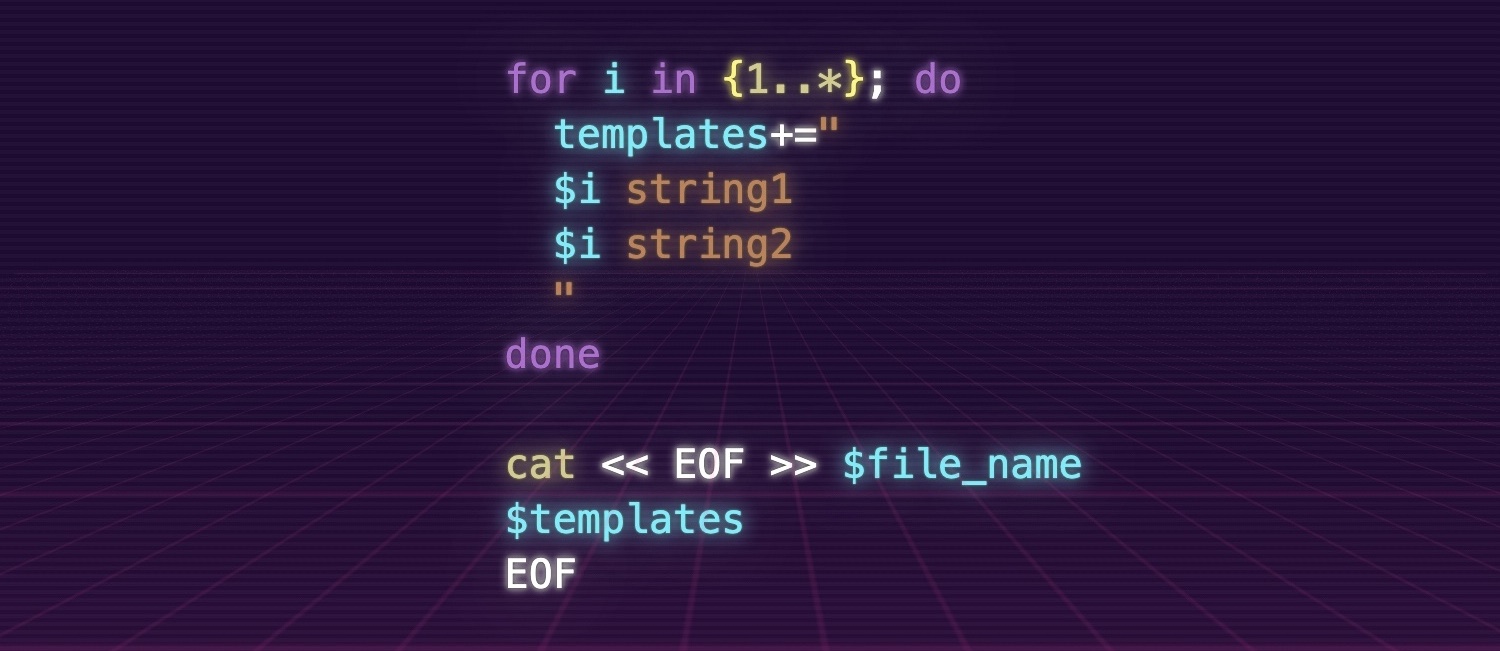
for i in {1..*}; do
templates+="
$i string1
$i string2
"
done
cat << EOF >> $file_name
$templates
EOF
message=$(
cat << EOF
string
EOF
)
echo "$message"
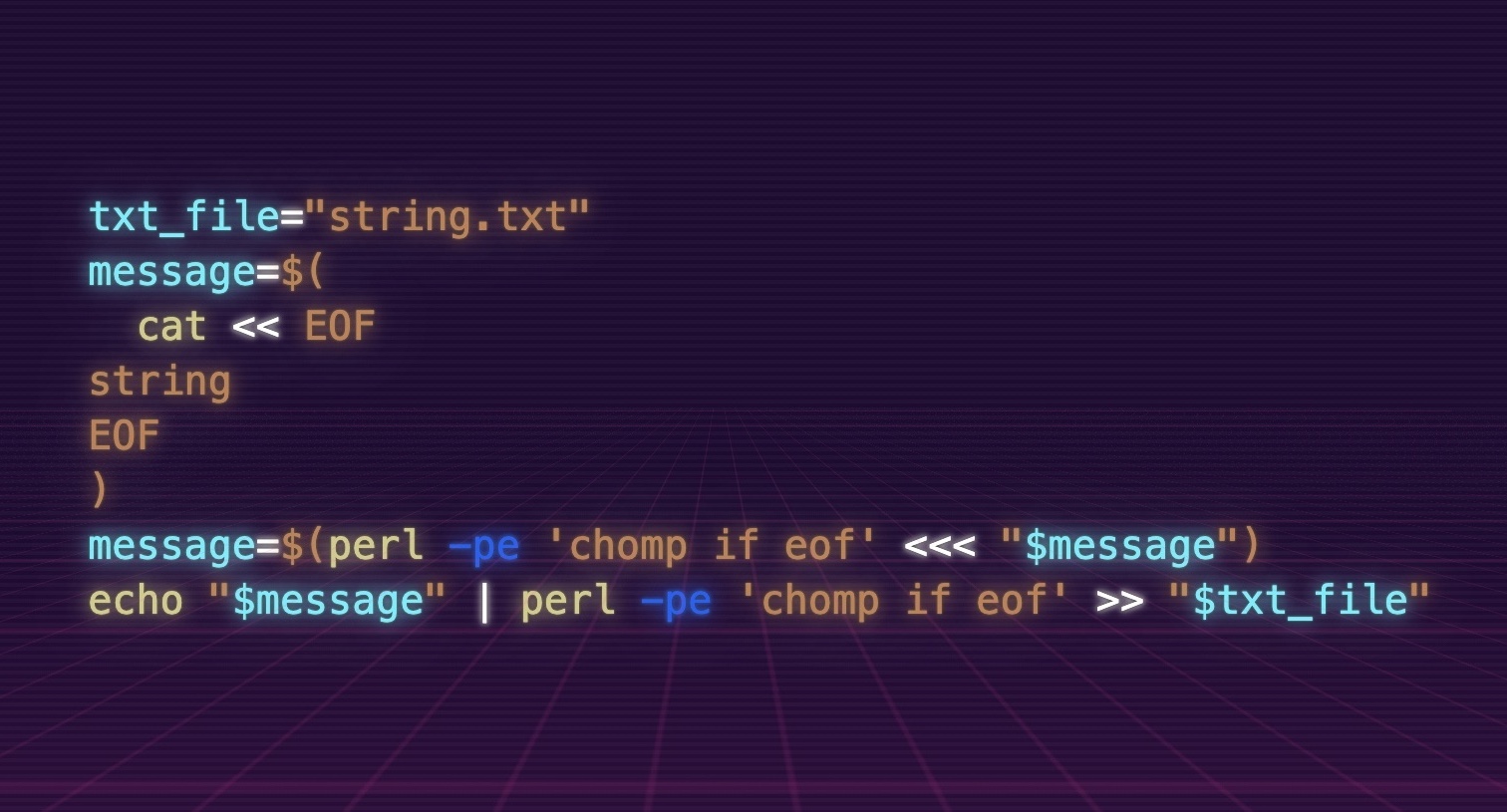
txt_file="string.txt"
message=$(
cat << EOF
string
EOF
)
message=$(perl -pe 'chomp if eof' <<< "$message")
echo "$message" | perl -pe 'chomp if eof' >> "$txt_file"
count=0
while IFS=, read -r col1 col2 col3 col4 col5 || [[ -n $col5 ]]; do
count=$((count + 1))
cat << EOF >> "$current_dir/$file"
$count
$col1
$col2
$col3
$col4
$col5
EOF
done < "$current_dir/$csv"
while IFS=, read -r col1 col2 col3 col4 col5 || [[ -n $col5 ]]; do
# 処理文
done < "$current_dir/$csv"
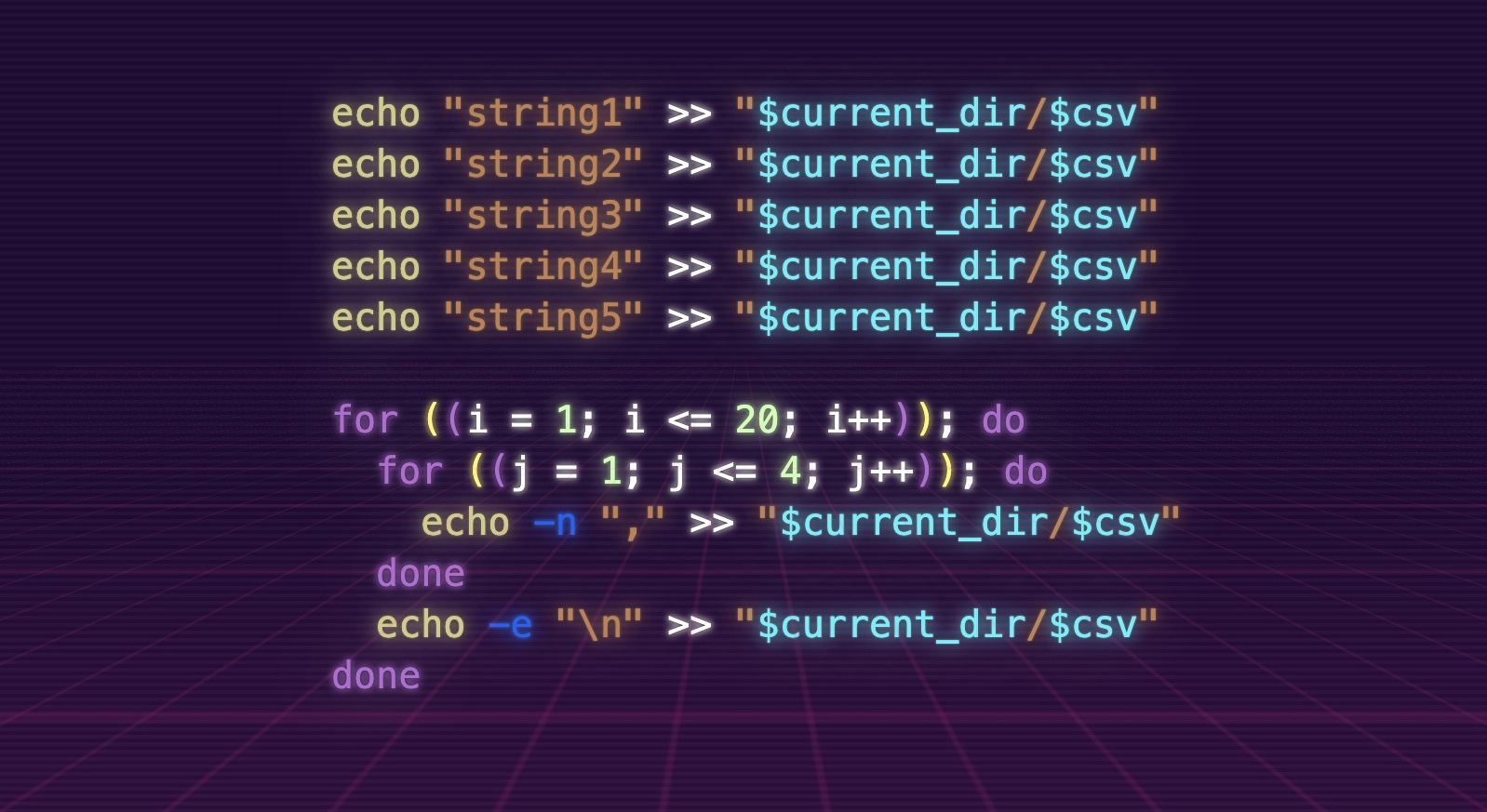
echo "string1" >> "$current_dir/$csv"
echo "string2" >> "$current_dir/$csv"
echo "string3" >> "$current_dir/$csv"
echo "string4" >> "$current_dir/$csv"
echo "string5" >> "$current_dir/$csv"
for ((i = 1; i <= 20; i++)); do
for ((j = 1; j <= 4; j++)); do
echo -n "," >> "$current_dir/$csv"
done
echo -e "\n" >> "$current_dir/$csv"
done
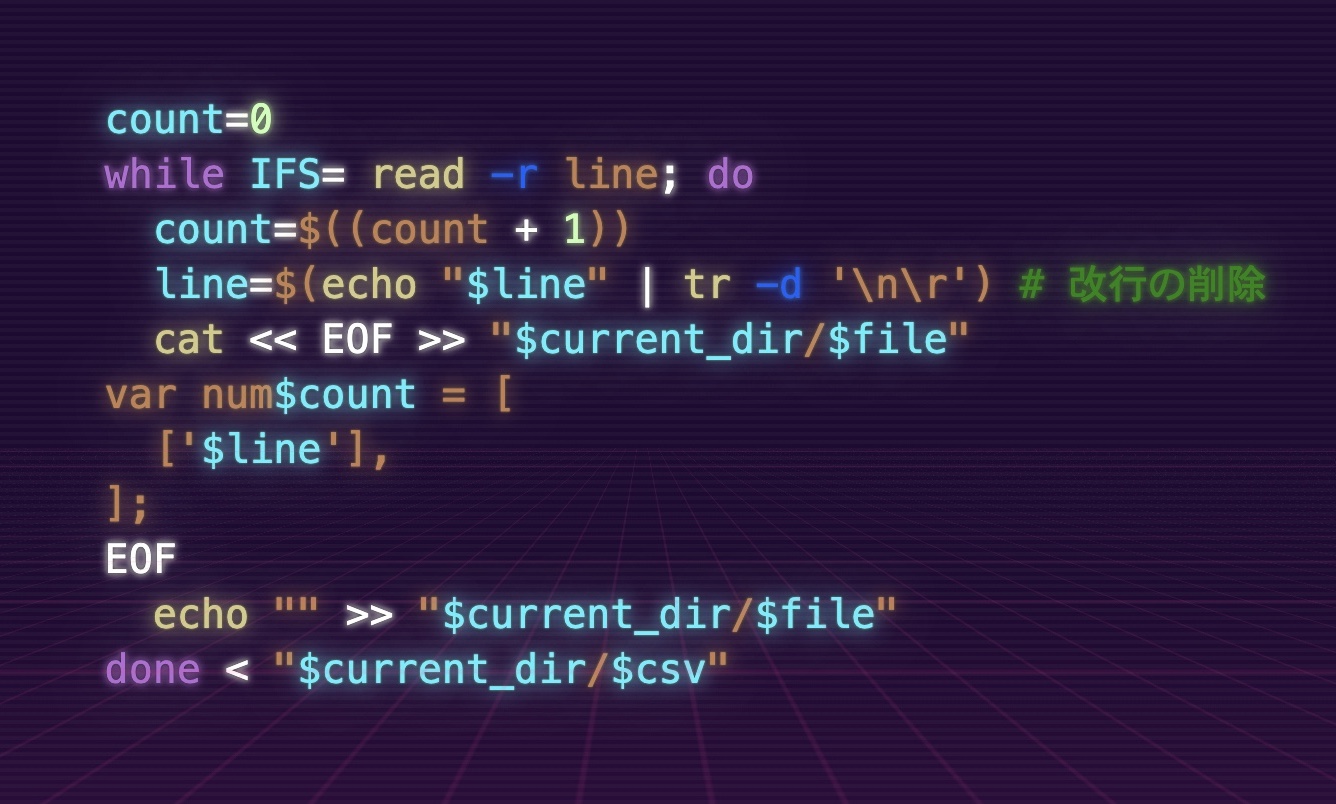
count=0
while IFS= read -r line; do
count=$((count + 1))
line=$(echo "$line" | tr -d '\n\r') # 改行の削除
cat << EOF >> "$current_dir/$file"
var num$count = [
['$line'],
];
EOF
echo "" >> "$current_dir/$file"
done < "$current_dir/$csv"
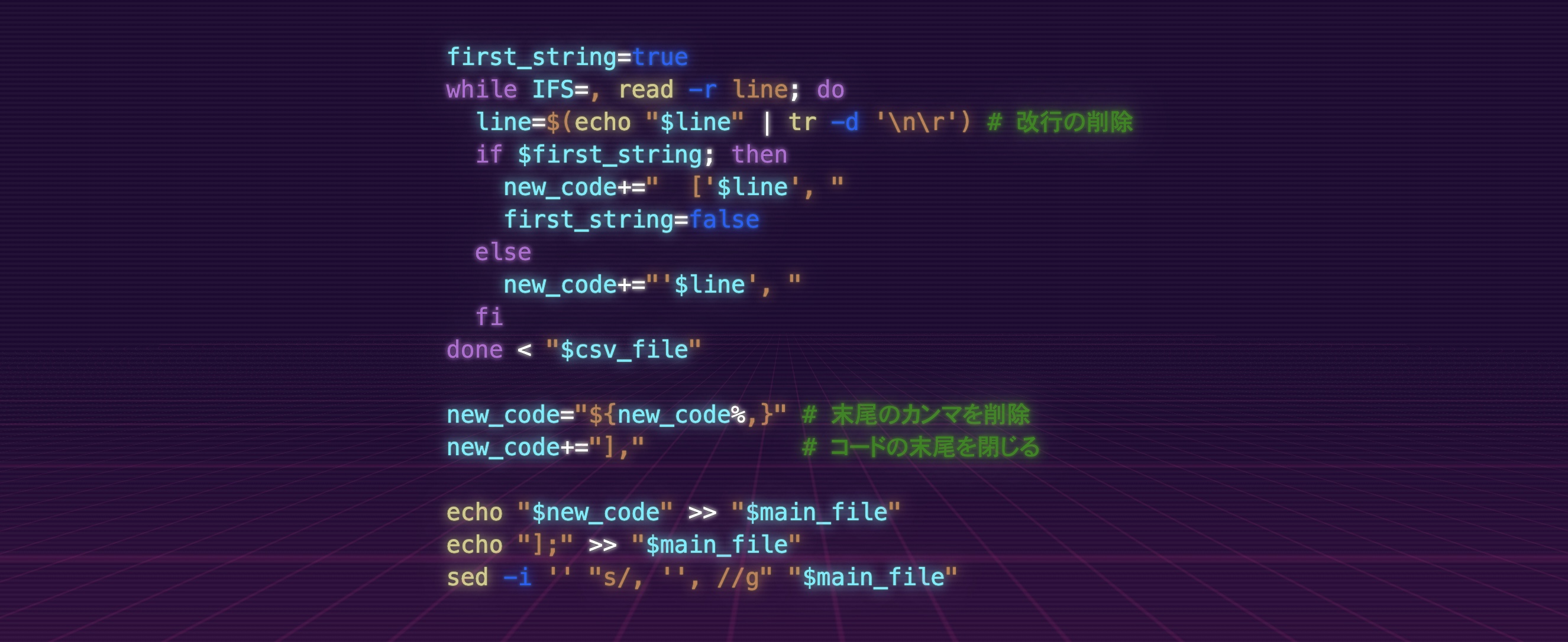
first_string=true
while IFS=, read -r line; do
line=$(echo "$line" | tr -d '\n\r') # 改行の削除
if $first_string; then
new_code+=" ['$line', "
first_string=false
else
new_code+="'$line', "
fi
done < "$csv_file"
new_code="${new_code%,}" # 末尾のカンマを削除
new_code+="]," # コードの末尾を閉じる
echo "$new_code" >> "$main_file"
echo "];" >> "$main_file"
sed -i '' "s/, '', //g" "$main_file"
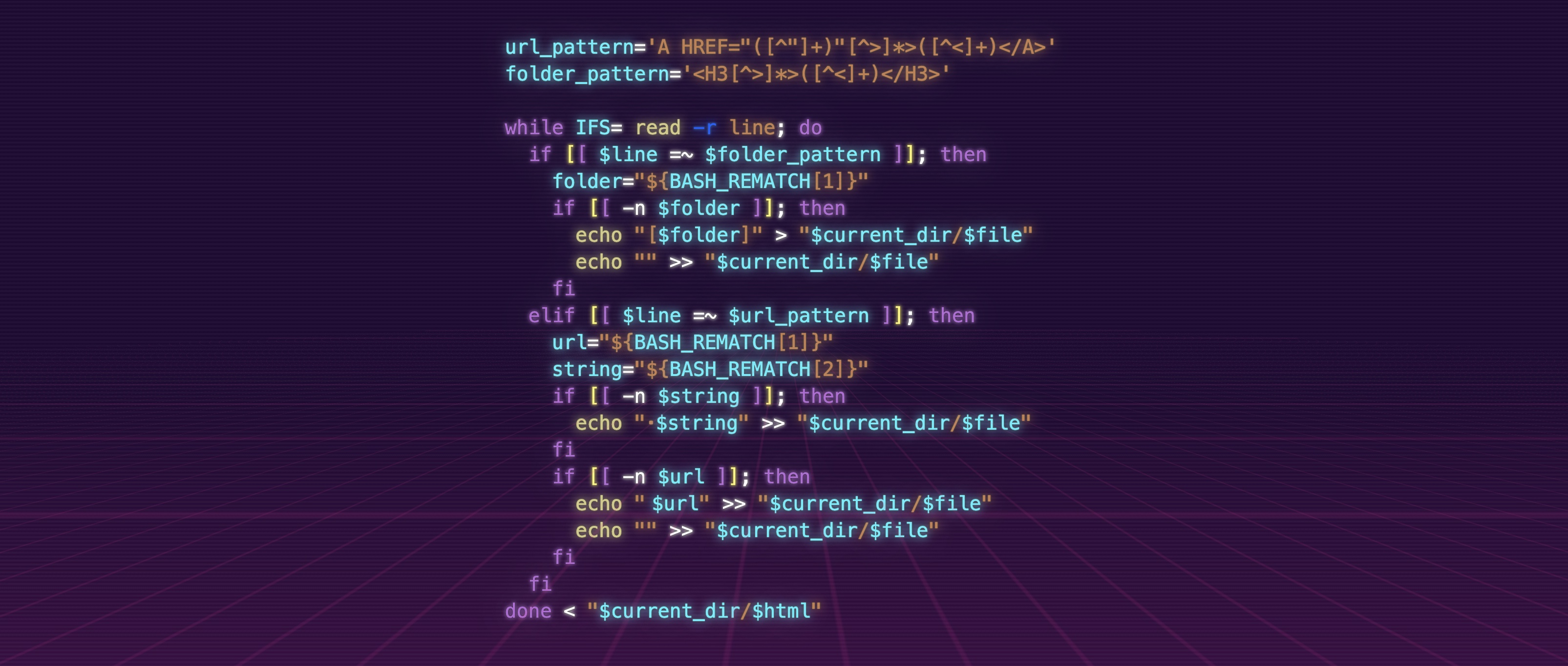
url_pattern='A HREF="([^"]+)"[^>]*>([^<]+)</A>'
folder_pattern='<H3[^>]*>([^<]+)</H3>'
while IFS= read -r line; do
if [[ $line =~ $folder_pattern ]]; then
folder="${BASH_REMATCH[1]}"
if [[ -n $folder ]]; then
echo "[$folder]" > "$current_dir/$file"
echo "" >> "$current_dir/$file"
fi
elif [[ $line =~ $url_pattern ]]; then
url="${BASH_REMATCH[1]}"
string="${BASH_REMATCH[2]}"
if [[ -n $string ]]; then
echo "・$string" >> "$current_dir/$file"
fi
if [[ -n $url ]]; then
echo " $url" >> "$current_dir/$file"
echo "" >> "$current_dir/$file"
fi
fi
done < "$current_dir/$html"
IFS=$'\n' # スペースをファイル名に含めるためにIFS(Internal Field Separator)を設定
if [ -e $volume ]; then
cd $volume || exit
for file in ls $(ls -a); do
files=$(basename "$file")
if [ -d "$files" ]; then
echo -e "\033[1;34m> $files\033[0m"
elif [ -f "$files" ]; then
echo -e "\033[1;37m> $files\033[0m"
fi
done
else
echo -e "\033[1;31m$(basename "$volume") が存在しません。\033[0m"
fi
disk_limit="19532000" # duからすれば10GB
disk_usage=$(du -s "$source" | cut -f1)
if [ "$disk_usage" -gt "$disk_limit" ]; then
echo "string"
exit 1
else
rsync --archive --human-readable--progress $source* $destination
fi
tree | sed 's/──//g; s/│/|/g;' | grep -vE "directories | files" > "$current_dir/$file"
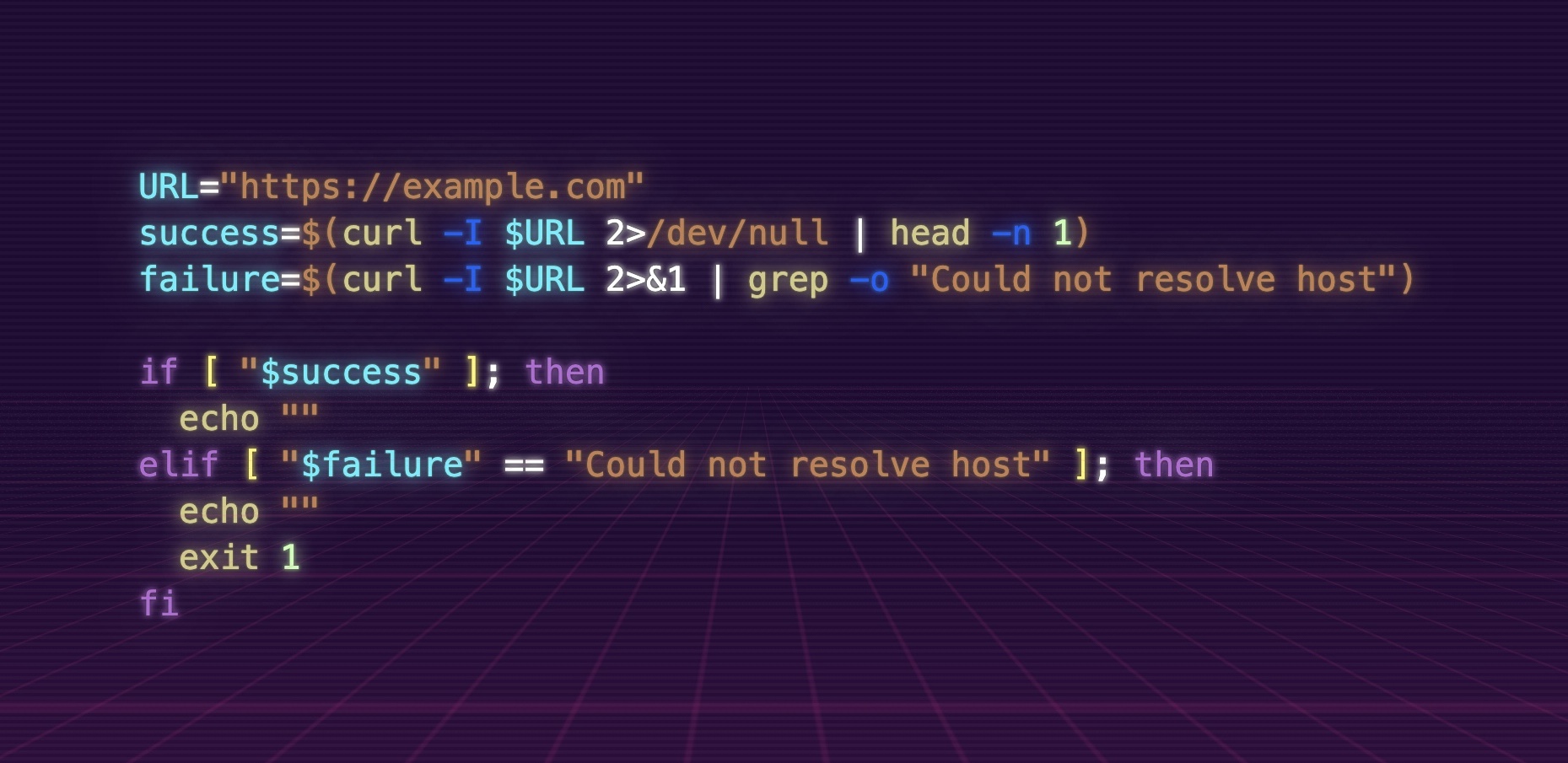
URL="https://example.com"
success=$(curl -I $URL 2>/dev/null | head -n 1)
failure=$(curl -I $URL 2>&1 | grep -o "Could not resolve host")
if [ "$success" ]; then
echo ""
elif [ "$failure" == "Could not resolve host" ]; then
echo ""
exit 1
fi
if command -v command_name &>/dev/null; then
function_name # ここにコマンドの名前を入力する
else
echo ""
fi
command_name
while [ $? -ne 0 ]; do
echo
echo ""
sleep 3
command_name
done
for i in {1..*}; do
templates+="string$i=\$(command_name \"\$variable\" | command_name)
"
done
cat << EOF >> $file_name
$templates
EOF
string="value"
for ((i = 0; i < ${#string}; i++)); do
echo -n -e "\033[1;36m${string:i:1}\033[0m"
sleep 0.01
done
logfile="string.log"
exec > >(tee -a "$logfile")
while IFS= read -r line || [[ -n $line ]]; do
trimmed_line=$(echo "$line" | sed -e 's/^[<space><tab>]*$//g') # 先頭と末尾の空白を削除
if [ -z "$trimmed_line" ]; then
echo >> "$current_dir/$csv" # 空行の場合もCSVの空行として出力する
else
echo -n "$trimmed_line," >> "$current_dir/$csv" # カンマで区切ってCSV形式の1行に書き出す
fi
done < "$current_dir/$file"
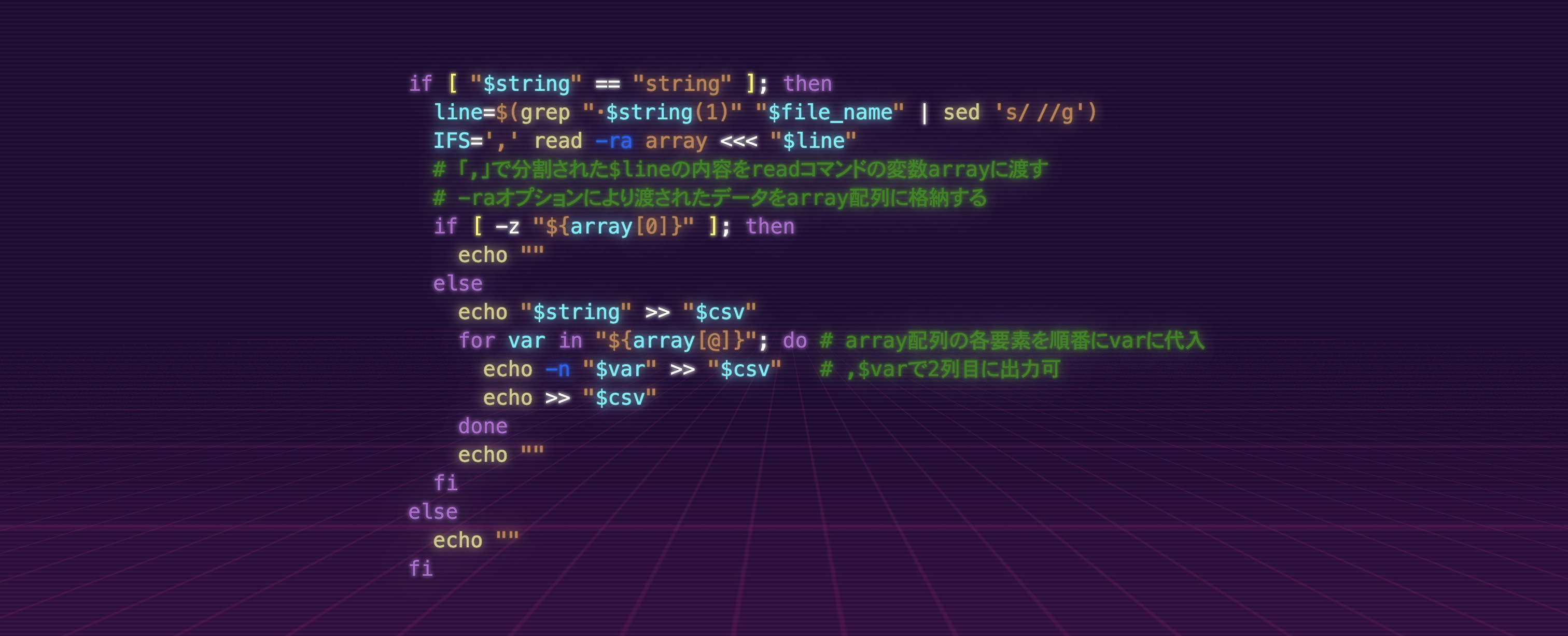
if [ "$string" == "string" ]; then
line=$(grep "・$string(1)" "$file_name" | sed 's/ //g')
IFS=',' read -ra array <<< "$line"
# 「,」で分割された$lineの内容をreadコマンドの変数arrayに渡す
# -raオプションにより渡されたデータをarray配列に格納する
if [ -z "${array[0]}" ]; then
echo ""
else
echo "$string" >> "$csv"
for var in "${array[@]}"; do # array配列の各要素を順番にvarに代入
echo -n "$var" >> "$csv" # ,$varで2列目に出力可
echo >> "$csv"
done
echo ""
fi
else
echo ""
fi
if [[ $first_line =~ ^([0-9]{4}/[0-9]{1,2}/[0-9]{1,2})\ ([0-9]{1,2}:[0-9]{1,2})\ (.+)$ ]]; then
date_parts="${BASH_REMATCH[1]}"
time_parts="${BASH_REMATCH[2]}"
title_parts="${BASH_REMATCH[3]}"
fi
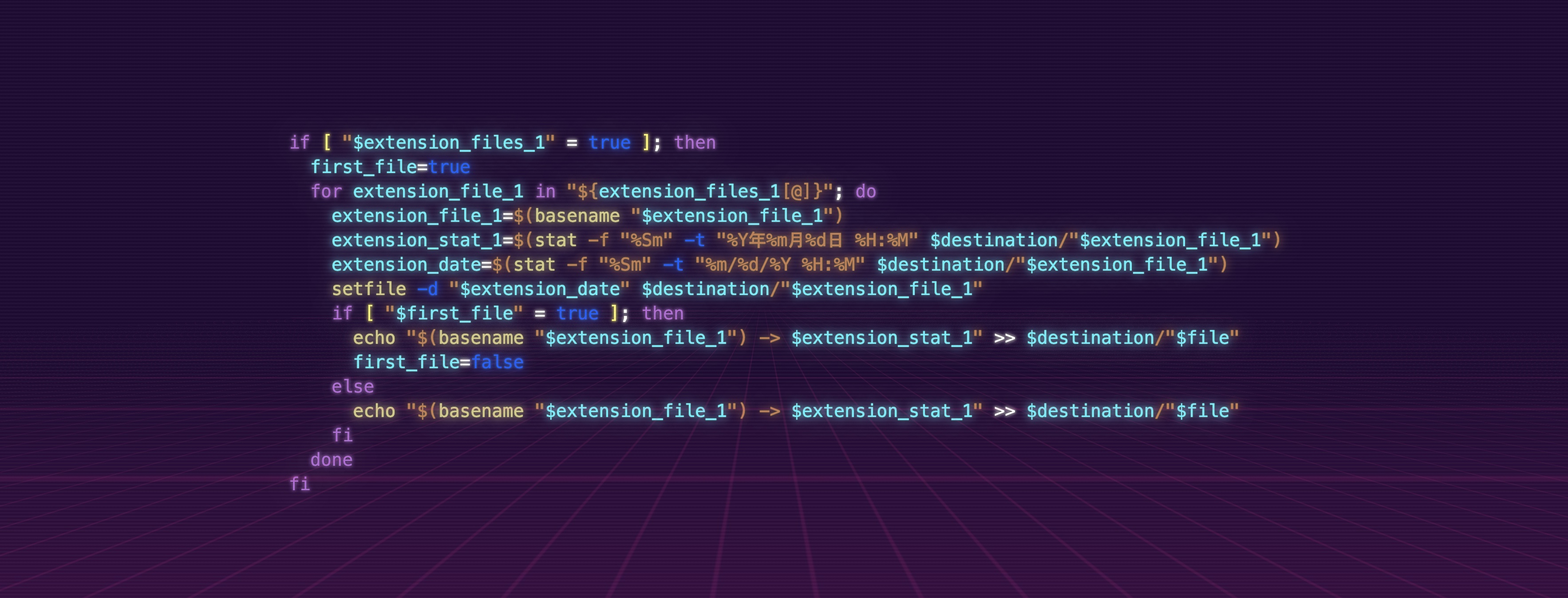
if [ "$extension_files_1" = true ]; then
first_file=true
for extension_file_1 in "${extension_files_1[@]}"; do
extension_file_1=$(basename "$extension_file_1")
extension_stat_1=$(stat -f "%Sm" -t "%Y年%m月%d日 %H:%M" $destination/"$extension_file_1")
extension_date=$(stat -f "%Sm" -t "%m/%d/%Y %H:%M" $destination/"$extension_file_1")
setfile -d "$extension_date" $destination/"$extension_file_1"
if [ "$first_file" = true ]; then
echo "$(basename "$extension_file_1") -> $extension_stat_1" >> $destination/"$file"
first_file=false
else
echo "$(basename "$extension_file_1") -> $extension_stat_1" >> $destination/"$file"
fi
done
fi
file_limit=48 # ファイル数の制限
file_count=0 # ファイル数のカウント
for file in "$src_volume/$directory"/*; do # 送信対象のファイルをループで処理
rsync --archive --human-readable --progress "$file" "$src_volume/$today"
((file_count++)) # 送信対象のファイル数をインクリメント
if [ $file_count -ge "$file_limit" ]; then # 送信対象のファイル数が制限に達したらループを終了
break
fi
done
rm_file_limit=48
rm_file_count=0
for file in "$src_volume/$directory"/*; do # 削除対象のファイルをループで処理
rm -v "$file"
((rm_file_count++)) # 削除対象のファイル数をインクリメント
if [ $rm_file_count -ge "$rm_file_limit" ]; then # 削除対象のファイル数が制限に達したらループを終了
break
fi
done
converted_string=$(awk '{printf "%s%s", (NR>1 ? (/^[.!?]/ ? "\n" : " "): ""), $0} END {print ""}' "$file")
echo -e "$converted_string" > "$file"
sed -e 's/ /\\n/g' -e 's/\n//g' -e 's/\\n\"//g' -e 's/\",/\n/g' "$file" > "$file.tmp"
mv "$file.tmp" "$file"
sed -i '' '/^[[:space:]]*$/d' "$file"
sed -i '' 's/,/\n/g' "$file" # csvの空列によって生まれる区切り文字「,」を改行に変換
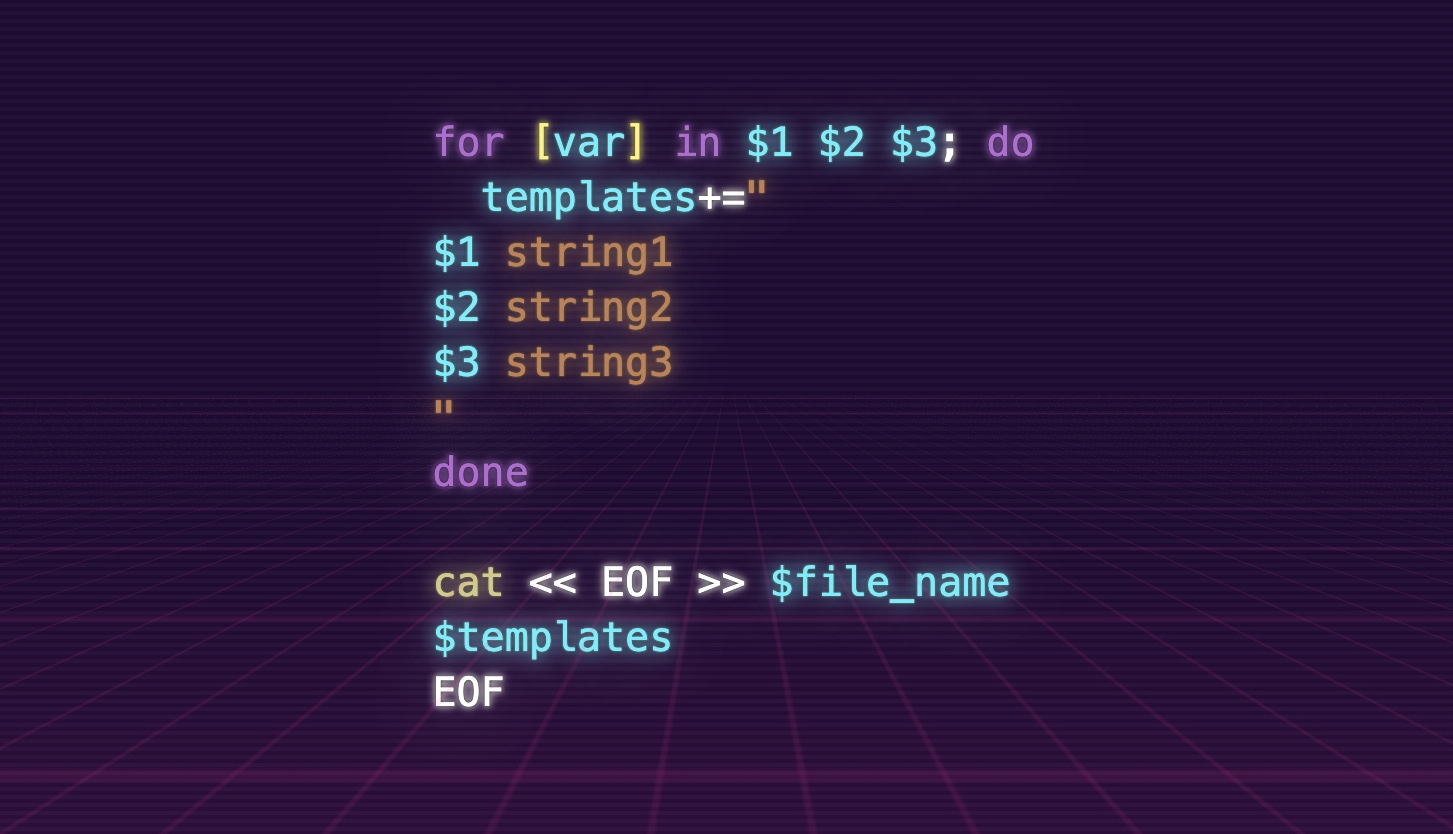
for [var] in $1 $2 $3; do
templates+="
$1 string1
$2 string2
$3 string3
"
done
cat << EOF >> $file_name
$templates
EOF
directory=$(find "$dir_name" -type d -iname '*' 2>/dev/null)
directory=$(basename "$directory")
if [ -s "$dir_name/$directory" ]; then
sleep 1
function_name # ここに関数の名前を入力する
echo
fi
sed -n 's/.*[マッチさせたい文字列]\(.*\)$/\1/p'
# (.*\)$は行末にある任意の文字列をキャプチャするためのもの
# /\1/pは正規表現でキャプチャされた部分を指す。pはその部分を表示するためのコマンド
sed -n 's/文字列[0-9]\{4\}\.拡張子\(.*\)$/\1/p'
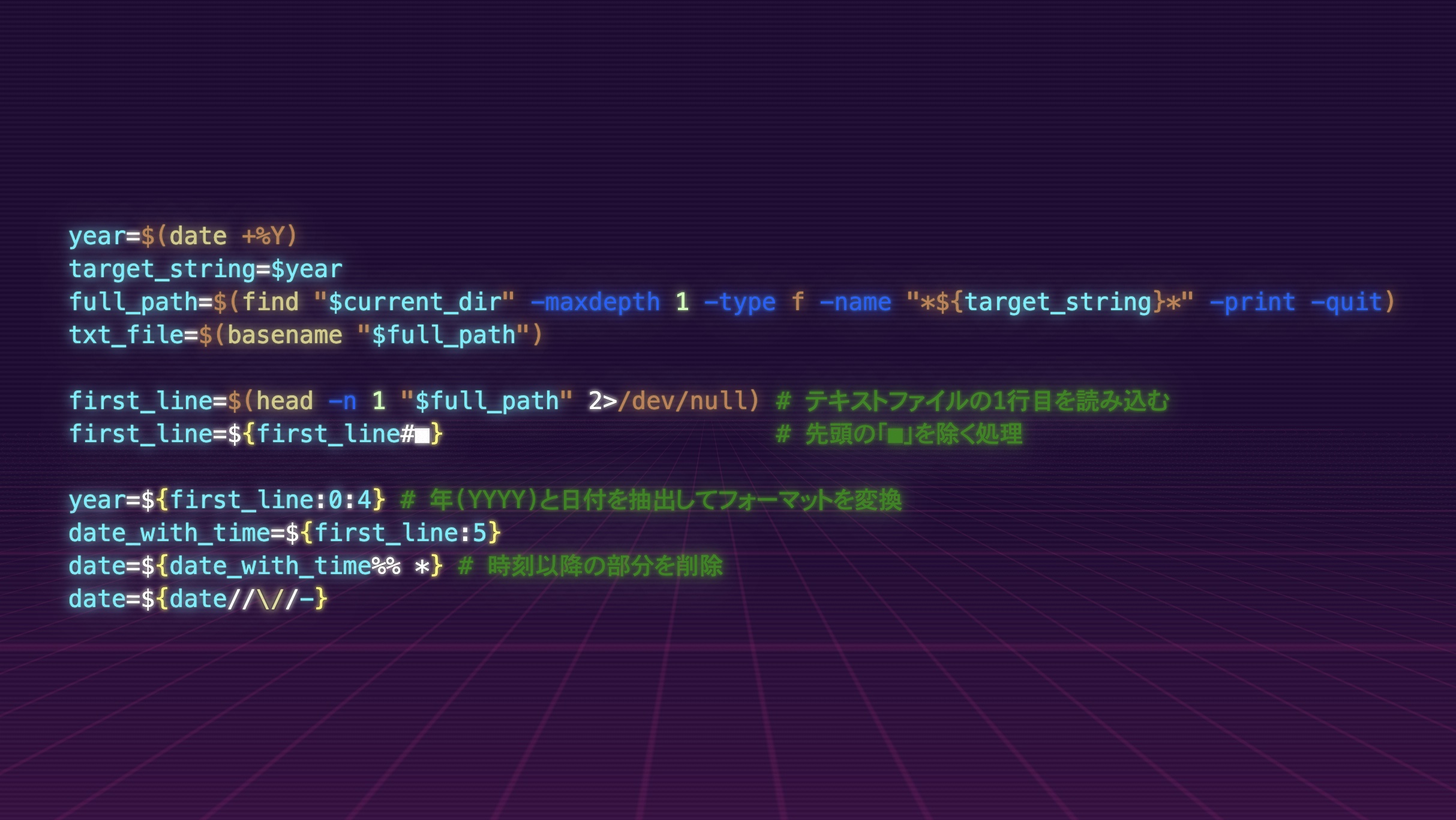
year=$(date +%Y)
target_string=$year
full_path=$(find "$current_dir" -maxdepth 1 -type f -name "*${target_string}*" -print -quit)
txt_file=$(basename "$full_path")
first_line=$(head -n 1 "$full_path" 2>/dev/null) # テキストファイルの1行目を読み込む
first_line=${first_line#■} # 先頭の「■」を除く処理
year=${first_line:0:4} # 年(YYYY)と日付を抽出してフォーマットを変換
date_with_time=${first_line:5}
date=${date_with_time%% *} # 時刻以降の部分を削除
date=${date//\//-}
current_dir=$(cd "$(dirname "$0")" && pwd)
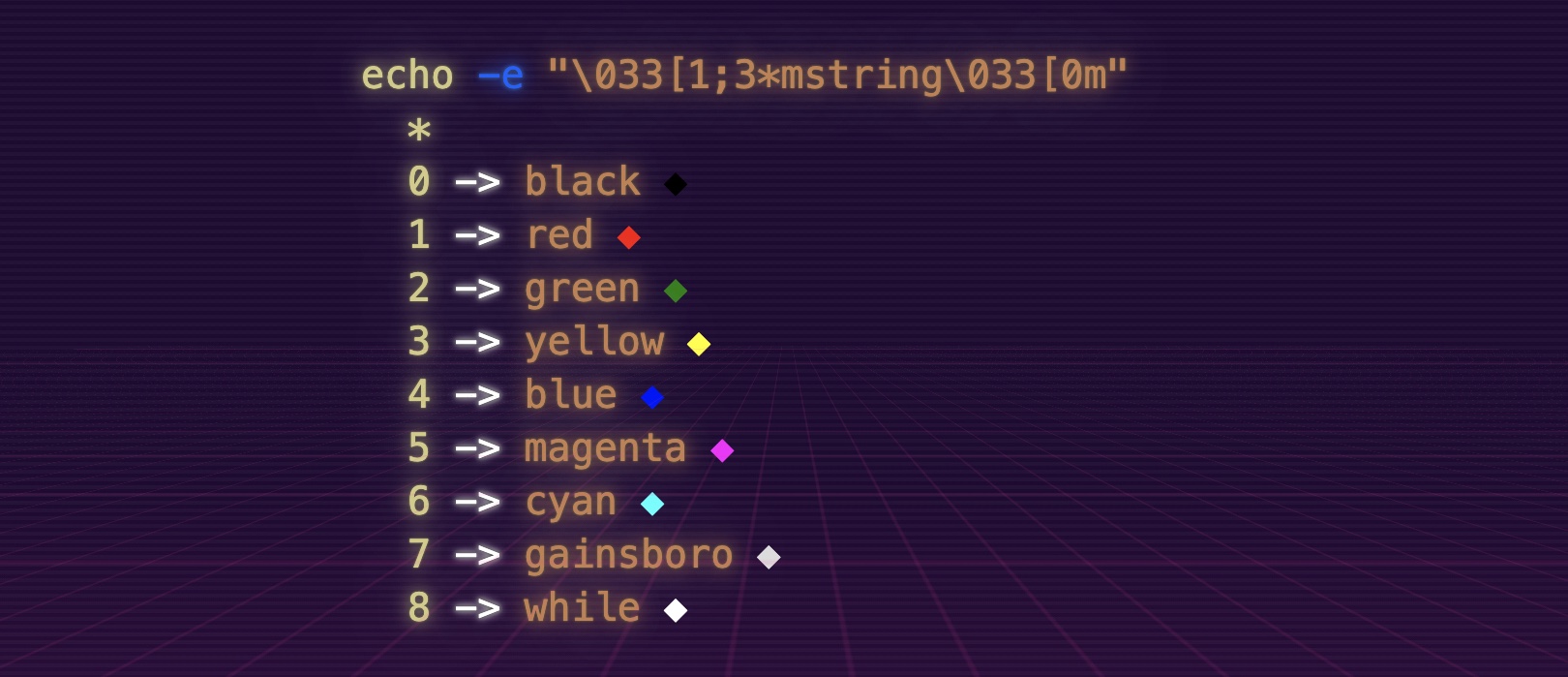
echo -e "\033[1;3*mstring\033[0m"
*
0 -> black ◆
1 -> red ◆
2 -> green ◆
3 -> yellow ◆
4 -> blue ◆
5 -> magenta ◆
6 -> cyan ◆
7 -> gainsboro ◆
8 -> while ◆
main_file → 処理を経て最終的に出力されるファイル
sub_file → main_fileの作成に必要なファイル
mid_file → 処理の途中で必要なファイル
define_* → 定義する
generate_* → 生成する
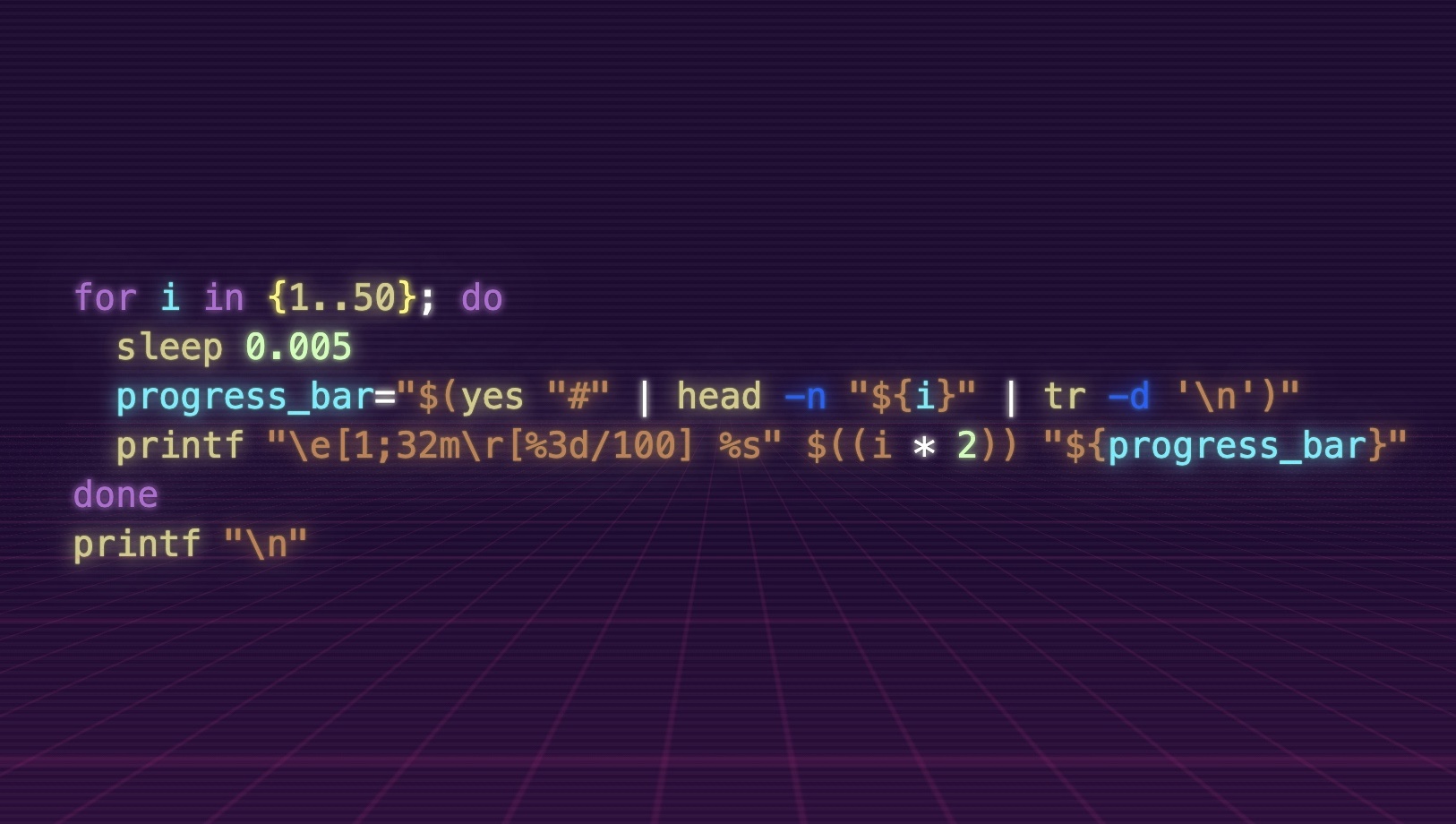
for i in {1..50}; do
arrow="\e[1;34m==>\e[0m"
sleep 0.005
progress_bar="$(yes "#" | head -n "${i}" | tr -d '\n')"
printf "\r$arrow \e[1;32mrm [%3d/100] %s" $((i * 2)) "${progress_bar}"
done
printf "\n"
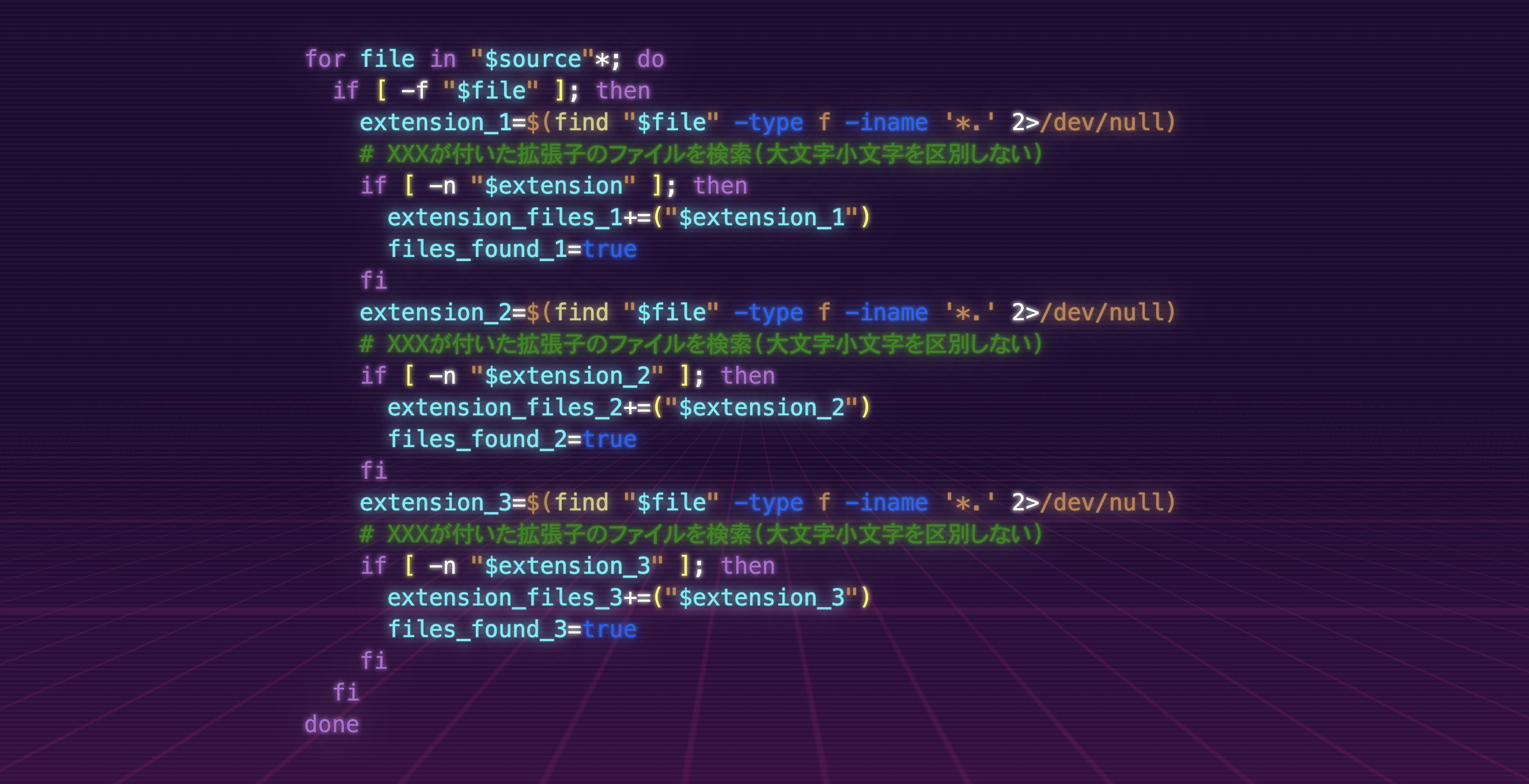
for file in "$source"*; do
if [ -f "$file" ]; then
extension_1=$(find "$file" -type f -iname '*.' 2>/dev/null)
# XXXが付いた拡張子のファイルを検索(大文字小文字を区別しない)
if [ -n "$extension" ]; then
extension_files_1+=("$extension_1")
files_found_1=true
fi
extension_2=$(find "$file" -type f -iname '*.' 2>/dev/null)
# XXXが付いた拡張子のファイルを検索(大文字小文字を区別しない)
if [ -n "$extension_2" ]; then
extension_files_2+=("$extension_2")
files_found_2=true
fi
extension_3=$(find "$file" -type f -iname '*.' 2>/dev/null)
# XXXが付いた拡張子のファイルを検索(大文字小文字を区別しない)
if [ -n "$extension_3" ]; then
extension_files_3+=("$extension_3")
files_found_3=true
fi
fi
done
array=()
while IFS= read -r -d '' files; do
array+=("$files")
done < <(find "$current_dir" -type f -name "*." -print0)
for file in "${array[@]}"; do # 配列の要素を一つずつ処理
while IFS= read -r line; do
echo "$line" >> "$file_name"
done < "$file"
done
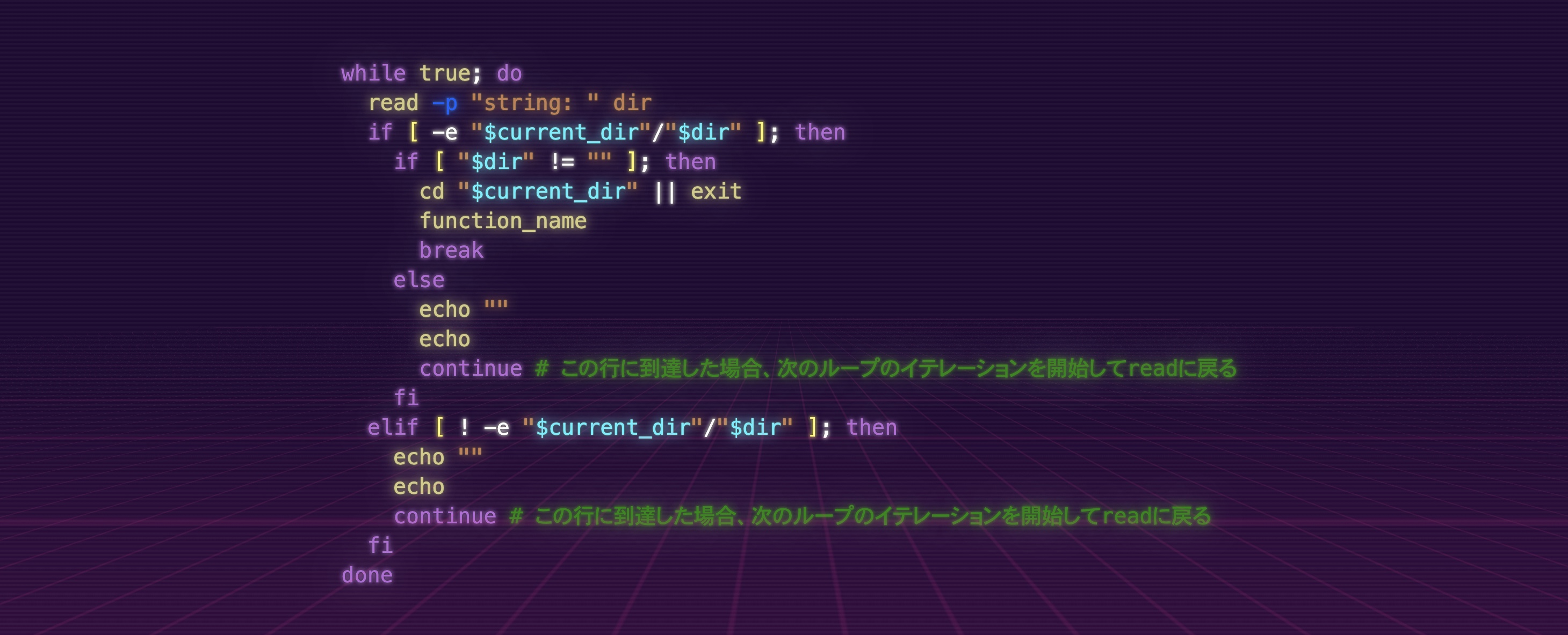
while true; do
read -p "string: " dir
if [ -e "$current_dir"/"$dir" ]; then
if [ "$dir" != "" ]; then
cd "$current_dir" || exit
function_name
break
else
echo ""
echo
continue # この行に到達した場合、次のループのイテレーションを開始してreadに戻る
fi
elif [ ! -e "$current_dir"/"$dir" ]; then
echo ""
echo
continue # この行に到達した場合、次のループのイテレーションを開始してreadに戻る
fi
done
var=$(cat /dev/urandom | LC_CTYPE=C tr -dc 'a-zA-Z0-9' | fold -w 5 | head -n 1 | sort | uniq)